
Calude Mythos è tra noi: prime impressioni
Anthropic ha rilasciato Claude Fable 5, il primo modello della nuova classe Mythos. Non è un semplice aggiornamento: è una categoria di modelli completamente nuova, al di sopra di Opus. Ne parlano tutti, le aspettative sono altissime, e per questo vale la pena separare quello che Anthropic dichiara da quello che l'esperienza d'uso racconta davvero.
Il modello più intelligente non è sempre quello giusto per il task che hai davanti.
Questa è una review basata su test diretti del modello, con casi d'uso concreti: scrittura di spec, sviluppo software, analisi di documenti, progettazione di interfacce, workflow multi-agent. I risultati sono stati a volte sorprendenti, in positivo e in negativo.
Mythos, Fable e la distinzione che conta
Prima di tutto, una chiarezza necessaria: esistono due cose che si chiamano "Mythos".
La prima è Mythos con la M maiuscola: ancora riservato a un gruppo selezionato di partner enterprise nell'ambito del progetto Project Glass, con accesso principalmente per use case legati alla cybersicurezza.
La seconda è Fable 5: il modello Mythos disponibile per tutti, con guardrail di sicurezza specifici attivati. Sono lo stesso modello, ma con una differenza operativa importante.
Quando oggi accedi a Claude Fable 5, stai usando Mythos con le protezioni attive. Mythos senza protezioni resta riservato a partner selezionati.
Cosa dice Anthropic
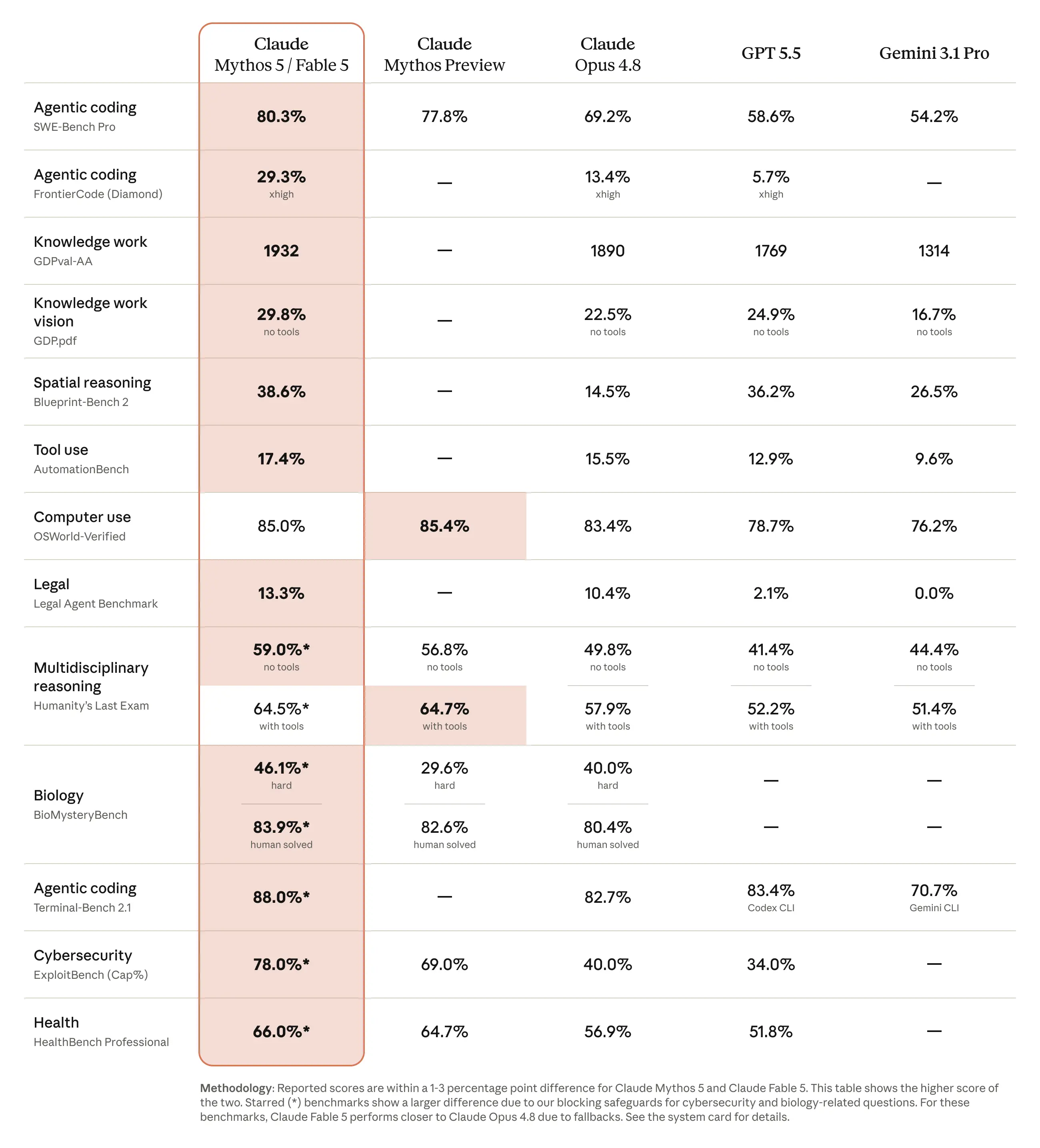
Anthropic lo presenta come una classe di modello completamente nuova. Le caratteristiche dichiarate sono:
- Benchmark: 80% su SWEBench Pro (uno standard per valutare la qualità nella scrittura di codice), con performance superiori a GPT-5.5 e Gemini 3.1 Pro
- Task lunghi e autonomi: progettato per lavori che durano ore o giorni, con la capacità di gestire sub-agent.
- Visione: capacità di analisi visiva superiore, con risultati ottimali su PDF e documenti complessi
- Impegno: lavora di più, verifica di più, costruisce con più cura, pensato per i lavori più ambiziosi
Il prezzo di questa ambizione: $10 per milione di token in input, $50 per milione di token in output. Una fascia sopra Opus, con un consumo di token (l'unità di misura del testo elaborato dai modelli AI) che Anthropic stessa stima circa il doppio rispetto ai modelli precedenti.
Dove funziona davvero bene

Visione e documenti. Questa è l'area in cui Fable 5 ha sorpreso di più. Testato contro più modelli nella formattazione di documenti ha prodotto risultati notevolmente migliori: spaziatura appropriata, leggibilità superiore, gestione dello spazio bianco più consapevole. Per chi lavora con parsing (estrazione e interpretazione del contenuto) di PDF o con documenti che richiedono attenzione al layout visivo, questo è un vantaggio concreto.
Problemi tecnici complessi. Il modello è costruito per fare il lavoro di un ingegnere senior: è esaustivo nell'analisi, esplora ogni angolo, non si ferma alla prima risposta. Su problemi tecnici difficili e multi-step, questa tendenza alla completezza paga. Fable 5 è stato testato anche come orchestratore di workflow multi-agent (architetture in cui più agenti AI lavorano in parallelo su sottocompiti), con risultati positivi in diversi casi.
È come lavorare con un ingegnere senior molto bravo: esplora tutto, non lascia nulla al caso, vuole essere sicuro al 120% di stare spedendo la cosa giusta.
Dove delude

La scrittura è quasi illeggibile. Quando si chiede a Fable 5 di scrivere spec, PRD (Product Requirements Document, il documento che descrive i requisiti di un prodotto), analisi o documenti di strategia, il risultato è tecnicamente completo ma praticamente indecifrabile. I documenti prodotti sono densi, pieni di riferimenti interni, con paragrafi lunghi e pochissima struttura visiva. L'informazione c'è tutta, ma il sentiero non si vede per via degli alberi. Per questo tipo di lavoro, Sonnet o Opus restano preferibili.
Design e frontend: delusione netta. Su richiesta di progettare un'interfaccia, Fable 5 ha prodotto risultati scadenti anche per gli standard AI: grigio, nero, rosso, senza cura estetica, senza senso dello spazio. Il team di Anthropic ha suggerito di inserire più dettaglii nel prompt, ma anche con istruzioni più precise, la qualità del design non è migliorata in modo significativo.
MVP troppo minimale. Quando si chiede di costruire il prototipo di un prodotto Fable 5 interpreta MVP (Minimum Viable Product, la versione minima funzionante) in modo molto restrittivo. Il risultato è spesso troppo ridotto per essere utile.
Multi-agent: promesse e instabilità. Sui workflow multi-agent, Fable 5 ha mostrato sia successi che blocchi. In alcuni test, dopo tre ore di lavoro autonomo, gli agenti si sono fermati senza completare il task. La valutazione: è probabilmente un problema di Claude Code più che del modello in sé, ma per chi vuole affidarsi a sessioni lunghe e non presidiate, la stabilità tecnica non è ancora garantita.
Il paradosso del modello troppo intelligente: sa tutto, scrive tutto, verifica tutto, e produce qualcosa che quasi nessuno riesce a leggere.
Il sistema di sicurezza: guardrail e fallback
Fable 5 ha classificatori specifici per quattro aree: cybersicurezza, biologia, chimica e distillazione (la tecnica con cui si trasferisce la conoscenza da un modello a un altro). Se un prompt viene classificato in una di queste categorie il sistema fa un graceful fallback (retrocessione elegante) a Opus 4.8, che continua il lavoro al suo posto.
Questa logica è disponibile anche via API (Application Programming Interface, l'interfaccia tecnica per integrare il modello in applicazioni): è possibile configurare un parametro opzionale che attiva automaticamente Opus 4.8 al prezzo di Opus quando il modello Mythos non può procedere.
Anthropic dichiara che il 95% delle sessioni su questo modello non ha attivato alcun fallback.
C'è anche una policy di retention di 30 giorni sui dati, usata solo per rilevare abusi, non per addestrare Claude.
Le novità che arrivano insieme al modello
Con il lancio di Fable 5 arrivano anche altre funzionalità:
- Claude Managed Agents in beta pubblica: la sandbox hosted di Anthropic per eseguire lavori agentici lunghi e complessi. Fable 5 è il modello di default in questo ambiente.
- Advisor Strategy: un'architettura in cui Fable 5 funge da senior advisor : pianifica, ragiona, supervisiona, mentre modelli più economici si occupano dell'esecuzione. Questo pattern era già usato da molti con Opus e Sonnet, e ora viene supportato ufficialmente nell'API e in Claude Code.
- Fallback API: parametro opzionale per gestire il passaggio a Opus 4.8 in modo programmatico, senza interruzioni per l'utente.
Quando usarlo, e quando no
La sintesi pratica di chi ha testato il modello su lavoro reale:
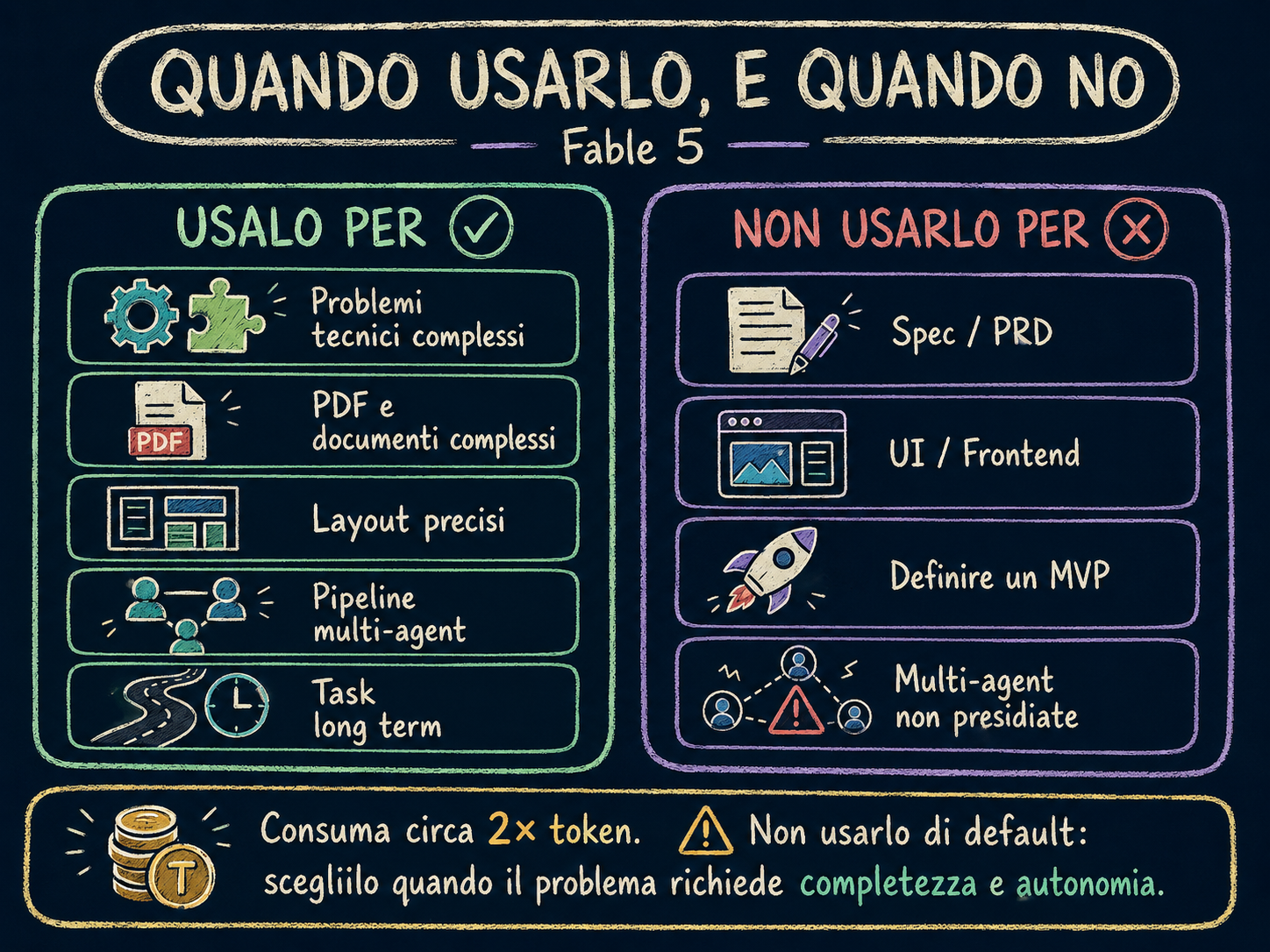
Usalo per:
- Problemi tecnici difficili dove la completezza conta più della velocità
- Analisi e parsing di PDF e documenti complessi
- Formattazione di layout visivi e documenti con struttura precisa
- Orchestrazione in pipeline multi-agent dove il dettaglio conta e non devi leggere direttamente l'output
- Task long term dove l'autonomia è necessaria
Non usarlo per:
- Scrittura di spec o PRD: il testo sarà troppo denso e difficile da leggere
- Progettazione di interfacce o lavoro frontend
- Definire un MVP: interpreterà "minimo" in modo troppo restrittivo
- Sessioni multi-agent non presidiate: la stabilità tecnica non è ancora garantita
A parità di task, Fable 5 consuma circa il doppio dei token rispetto ai modelli precedenti. Non è il modello da usare per default, è il modello da scegliere quando il problema lo richiede davvero.
In conclusione
Fable 5 esiste. Funziona. E su certi compiti fa cose che i modelli precedenti non facevano. Ma non è una risposta universale: è uno strumento da posizionare con precisione all'interno di uno stack, non un sostituto per tutto il resto.
